Tagged: Virtual machine
Assessing your Infrastructure for VDI with real data – Part 2 of 2 – Analysis
For VSI, we established that using analysis tools was a necessity, and VMware originally provided wonderful Capacity Planner tool. However, it soon became evident that for VDI, it is even more important to use analysis tools. That is because for VDI, when you buy hardware and software, the investment is generally higher. You need a lot more, faster storage. You need many servers and a fast network. So the margin of error is smaller.
Consequently, using Liquidware FIT or ControlUp is essential. There are now many tools on the market, like Lakeside Systrack or Nexthink.
So how do you analyze your physical desktops for VDI?
First, buy a license for the Liquidware FIT tool (per user, inexpensive), or buy an engagement from your friendly Valued Added Reseller or Integrator who is a Liquidware partner. If you buy a service from a partner, then usually up to 250 desktop license will be included with the service.
Here, I will talk about services of the partner because that is what I do. However, if you are doing this yourself, just apply the same steps.
You will need to provide your partner’s engineer with space for 2 small Liquidware virtual appliances. The only gotcha is that you want them on the fastest storage you have (SSD preferable). That is because on slower storage, it takes much longer to process any analysis or reports.
The engineer will come and install the 2 appliances into your vSphere. Then, the engineer will give you an EXE or MSI with an agent. Usually, you can use the same mechanism you already use to install software on your desktops to distribute the agent. For example, distribution tools like Microsoft SCCM, Symantec Altiris, LANDesk, and even Microsoft Group Policy will all be good. If you don’t have a mechanism for software distribution, then your engineer can use a script to install the agents on all PCs.
Make sure to choose a subset of your PCs, and at least some from each possible group of similar users (Accounting, Sales, IT, etc.). Your sample size could be about 10-25% of total user count. Obviously, the higher the analysis percentage, the more accuracy you get. But the goal here is not 100% accuracy – it’s impossible to achieve 100%. Assessment and performance analysis is an art as much as a science. Thus, you need just enough users to get a ballpark estimate of what hardware you need to buy. Also, run the assessment for 1 month preferably, or at a bare minimum 2 weeks. The time of the start of the data collection above should start from the time you deploy your last user with the Liquidware agent.
Your partner engineer will need remote access, if possible, to check on the progress of the installation. First, the engineer will check if the agents are reporting successfully back to the Liquidware appliances. During the month, the engineer will make sure agents are reporting and data can be extracted from the appliance.
In the middle of the assessment, engineer will do a so-called “normalization” of the data. That is to make sure the results are compatible with rules of thumb for analysis. If necessary, the engineer will readjust thresholds and recalculate the data back to the beginning.
At the end of 30 days, the engineer will generate a machine-made report on the overall performance metrics, and will present the report to you.
At some partners, for an extra service price, the engineer will go further, and will analyze the report for the amount and performance parameters of hardware you need. In addition, the engineer will create a written report and present all the data to you.
In either case, you will know which desktops have the best score for virtualization, and which ones you should not virtualize. If you go with more advanced report services from your partner, then you will also understand how to map the results to hardware and further insights.
One way of mitigating bad VDI sizings is to also use a load simulation tool like LoginVSI. However, LoginVSI is only useful for clients who can afford to buy similar equipment for the lab that they will buy for production. Using LoginVSI, you can test robotic (fake) users doing tasks that normal users will do in VDI. LoginVSI allows you to have a ballpark hardware number that is good. However, the LoginVSI number does not have real user experience data. For that, you need tools like Liquidware FIT and associated work to determine proper VDI strategy.
Understanding what your current user experience is, and also how that experience could be accommodated with virtual desktops is essential to VDI. You should do this assessment before buying your hardware. Doing an assessment ensures that your users get the same experience or better on the virtual desktop as they have on the physical desktop (the holy grail of VDI).
Renaming Virtual Disks (VMDK) in VMware ESXi
Symptom:
You have just cloned a VM, and would like to rename your VMDKs to match the new name of the clone.
When you try to rename a VMDK in the GUI Datastore Browser in vSphere client, you get a message:
“At the moment, vSphere Client does not support the renaming of virtual disks”
How do you go around the message?
Instructions:
- Lookup the name of your Datastore and your VM in the GUI.
- Start SSH service.
- Login as root to your ESXi host.
- In a SSH session type the following commands. Substitute the name of your Datastore for STORAGENAME and your VM for VMNAME.
- cd /vmfs/volumes/STORAGENAME/VMNAME
- Substitute the name of your old VMDK for OLDNAME and your new VMDK for NEWNAME. Remember – everything is case sensitive.
- vmkfstools -E ./OLDNAME.vmdk ./NEWNAME.vmdk
The lure of Hyper-Converged for VDI
So you decided to implement Virtual Desktop Infrastructure (VDI). Virtual desktops and app delivery sound sexy, but once you’ve started delving into the nitty gritty, you quickly realize that VDI has many variables. In fact, so many, that you start to feel overwhelmed.
At this point you have a couple of options. First, you can keep doing this yourself, but that will take valuable time. You can hire a VDI engineer to your team, but that also tales time and money to find a great engineer.
Another option is to hire a Value Added Reseller that has done VDI a hundred times. Great idea – I will love you forever, and will do great VDI for you. But I can be expensive.
One particular sticking point in VDI is the sizing of the hardware for the environment. If you undershoot the amount of compute, storage, memory or networking, you risk having unhappy users with underpowered virtual desktops. If you overshoot, you may be chastised for overspending.
Too often I have seen the user profile not properly examined, sized etc. The result is that the derived virtual desktop is low on memory or CPU. The user immediately blames the new technology, not even assigning blame to something they may have done. But the real performance problem culprit may lie somewhere else. However, the user just had his shiny physical machine taken away, and it was replaced with something intangible. Of course, all the problems, whether related to VDI or not, will be blamed on VDI, and possibly the VDI sizing. The bad buzz spreads through the company. Such buzz kills your VDI project faster than performance problems.
So, what is one way to avoid thinking about sizing? Hyper-Converged.
Hyper-Converged means a node in a cluster has a little bit of everything – compute, storage, memory, network. Each node is generally the same but there could be different types of nodes – for example, Simplivity has some nodes with everything, and some nodes only doing compute.
Since most nodes are the same, once you figured out how many average Virtual Desktops in a specific profile fit on a node, you can just keep adding nodes for scalability.
In fact, Nutanix capitalized on that brilliantly when they announced the famous guarantee – once the customer says how many users they want to put on Nutanix, the vendor will provide enough Hyper-Converged nodes to have a great user experience. The guarantee was hard to enforce on both the customer end and Nutanix end. But the guarantee sure had lots of marketing power. Time and time again I heard it from customers and other VARs. The guarantee was a placebo for making VDI easier.
Consequently, you should not just rely on a guarantee for VDI sizing. Sizing should be verified with load simulation tools like LoginVSI and View Planner. Then, the profile of your actual user should be evaluated by collecting user experience data with a tool like Liquidware FIT or Lakeside SysTrack.
Once the data is collected and analyzed, you can decide what number of Hyper-Converged nodes to buy. Hyper-Converged makes the sizing easy because you always deal with uniform nodes.
Once you are in production, you should be monitoring user experience constantly with a tool like Liquidware UX. UX will allow you to always have a solid idea of what your user profiles to. As a result, you can confidently say, “On my Hyper-Converged node I can host up to 50 users.” Thus, if you grow to 100 users, you need 2 Hyper-Converged nodes.
Saying the above is the holy grail of scalability. And therein lies the lure of Hyper-Converged – as a basic VDI building block. That is why Hyper-Converged companies started with strong VDI stories, and only later began marketing for Virtual Server Infrastructure.
And any technology that makes VDI easier, even by one iota, makes VDI more popular. Hail Hyper-Converged for VDI!
Assessing your Infrastructure for VDI with real data – Part 1 of 2 – History
It is now a common rule of thumb that when you are building Virtual Server Infrastructure (VSI), you must assess your physical environment with analysis tools. The analysis tools show you how to fit your physical workloads onto virtual machines and hosts.
The golden standard in analysis tools is VMware’s Capacity Planner. Capacity Planner used to be made by a company called AOG. AOG was analyzing not just for physical to virtual migrations, but was doing overall performance analysis of different aspects of the system. AOG was one of the first agentless data collections tools. Agentless was better because you did not have to touch each system in a drastic way, there was less chance of drivers going bad or performance impact to the target system.
Thus, AOG partnered with HP and other manufacturers, and was doing free assessments for their customers, while getting paid by the manufacturer on the backend. AOG tried to sell itself to HP, but HP, stupidly, did not buy AOG. Suddenly, VMware came from nowhere and snapped up AOG. VMware at the time needed an analysis tool to help customers migrate to the virtual infrastructure faster.
When VMware bought AOG, VMware dropped AOG’s other analysis business, and made AOG a free tool for partners to analyze migrations to the virtual infrastructure. It was a shame, because AOG’s tool, renamed to Capacity Planner, was really good. Capacity Planner relies solely on Windows Management Instrumentation (WMI) functions that is already built into Windows and is collecting information all the time. Normally, WMI discards information like performance, unless it is collected somewhere by choice. Capacity Planner just enabled that choice, and collected WMI performance and configuration data from each physical machine.
When VMware entered the Virtual Desktop Infrastructure (VDI) business with Horizon View, it lacked major pieces in the VDI ecosphere. One of the pieces was profile management, another piece was planning and analysis, another piece was monitoring. Immediately, numerous companies sprang to life to help VMware fill the need. Liquidware Labs (where the founder worked for VMware) was the first to come up with a robust planning and analysis tool in Stratusphere FIT, then with monitoring tool in Stratusphere UX. Lakeside SysTrack came on the scene. VMware used both internally, although the preference was for Liquidware.
Finally, VMware realized that the lack of analysis tool for VDI, made by VMware, was hindering them. But what they failed to realize, was that such tool already existed at VMware for years – Capacity Planner. The Capacity Planner team was neglected, so rarely would any updates were done to the tool. However, since Capacity Planner could already analyze physical machines for performance, it was easy to modify the code to collect information on virtualizing physical desktops, in addition to servers.
Capacity Planner code was eventually updated with desktops analysis. All VMware partners were jumping with joy – we now had a great tool and we did not have to relearn any new software. I remember that I eagerly collected my first data, and began to analyze the data. After analysis, the tool told me I needed something like twenty physical servers to hold 400 virtual desktops. Twenty desktops per server? That sounded wasteful. I was a beginner VDI specialist then, so I trusted the tool but still had doubts. Then I did a few more passes at the analysis, and kept getting wildly different numbers. Trusting my gut instinct, I decided to redo one analysis with Liquidware FIT.
Of course, Liquidware FIT has agents, so I used it, but always thought that it would be nice not to have agents. So VMware’s addition of desktop analysis to agentless Capacity Planner was very welcome. So, back to my analysis, after running Liquidware FIT, I came up with completely different numbers. I don’t remember what they were – perhaps 60 desktops per physical server, or something else. But what I do remember was that Liquidware’s analysis made sense, where Capacity Planner did not. My suspicions about Capacity Planner as a tool were confirmed by VMware’s own VDI staff, who, when asked if they use Capacity Planner to size VDI said, “For VDI, avoid Cap Planner like the plague, and keep using Liquidware FIT.”
As a result, I kept using Liquidware FIT since then, and never looked back. While FIT does have agents, now I understand that getting metrics like Application load times and User Login delay is not possible without agents. That is because Windows does not include such metrics in WMI. Therefore, a rich agent is able to pick up many more user experience items, and thus do much better modeling.
Moving a VMware Horizon View virtual desktop between separate Horizon View environments
Requirements:
Sometimes you may build two distinct VMware Horizon View environments for separate business units, for Disaster Recovery, or for testing purposes.
In that case, a need may arise to move a virtual desktop between the independent Horizon View infrastructures.
Assumptions:
There are many ways Horizon View may be configured. However, this article assumes the following settings in both environments:
- Manual, non-automated, dedicated pools for virtual desktops
- Full clone virtual desktops
- All user data is contained inside the virtual desktop, most likely on drive C
- All virtual desktop disks (vmdks, C and others) are contained within the same VM directory on the storage
- Storage is presented to ESXi through the NFSv3 protocol
- Microsoft Active Directory domain is the same across both sites
- VLANs/subnets the same or different between the two sites
- DHCP is configured for the desktop VM in both sites
- Virtual desktop has Windows 7 or Windows 10 operating system
- Connection Servers do not replicate between environments
- No Cloud Pod federation
- Horizon View v7.4
- vCenter VCSA 6.5 Update 1e
- ESXi 6.5 for some hosts and 6.0 Update 3 for other hosts
There are other ways to move a virtual desktop when the Horizon View is setup with automation and Linked Clones, but they are subject for a future article.
The first Horizon View infrastructure will be called “Source” in this article. The second Horizon View infrastructure, where the virtual desktop needs to be moved, will be called “Destination” in this article.
Instructions:
- Record which virtual desktop names are assigned to which Active Directory users on the Source side. You can do that by Exporting a CSV file from the Pool’s Inventory tab.
- If the Source Horizon View infrastructure is still available (not destroyed due to a disaster event), then continue with the following steps on the Source environment. If the Source Horizon View infrastructure has been destroyed due to a disaster, go to Step 9.
- Power off the virtual desktop. Ensure that in Horizon View Manager you don’t have a policy on your pool to keep powering the virtual desktop on.
- In Horizon View Manager, click on the pool name, select the Inventory tab.
- Right click the desktop name and select Remove.
- Choose “Remove VMs from View Manager only.”
- In vSphere Web Client, right click the desktop VM and select “Remove from Inventory.”
- Unmount the NFSv3 datastore that contains the virtual desktop from Source ESXi hosts.
- At this point how the datastore gets from Source to the Destination will vary based on your conditions.
- For example, for testing purposes, the NFSv3 datastore can be mounted on the Destination hosts.
- In case of disaster, there could be storage array technologies in place that replicate the datastore to the Destination side. If the Source storage array is destroyed, go to the Destination storage array and press the Failover button. Failover will usually make the Destination datastore copy Read/Write.
- Add the NFSv3 datastore that contains the virtual desktop to the Destination ESXi hosts, by going through the “New Datastore” wizard in vSphere Web Client.
- Browse the datastore File structure. Go to the directory of the virtual desktop’s VM, find the .vmx file.
- Right click on the .vmx file and select “Register VM…”
- Leave the same name for the desktop VM as offered by the wizard.
- Put the desktop VM in the correct VM folder and cluster/resource pool, that is visible by the Destination’s Horizon View infrastructure.
- Edit the desktop VM’s settings and select the new Port Group that exists on the Destination side (if required).
- Power on the desktop VM from the vSphere Web Client.
- You might get the “This virtual machine might have been moved or copied.” question.
- When vSphere sees that the storage path of the VM does not match what was originally in the .vmx file, you might get this question.
- Answering “Moved” keeps the UUID of the virtual machine, and therefore the MAC address of the network adapter and a few other things.
- Answering “Copied” changes the UUID of the virtual machine, and therefore the MAC address of the network adapter and a few other things.
- In the majority of cases (testing, disaster recovery), you will be moving the desktop virtual machine from one environment to another. Therefore, answer “I Moved It,” to keep the UUID and thus the MAC address the same.
- Wait until the desktop virtual machine obtains the IP address from the Destination’s DHCP server, and registers itself with the DNS server and Active Directory.
- Remember, we are assuming the same Active Directory domain across both sites. As a result, the desktop VM’s AD computer name and object will remain the same.
- Monitor the IP address and DNS assignment from the vSphere Web Client’s Summary tab for the desktop VM.
- In Destination’s Horizon View Manager, click on the Manual, Full Clone, Non-automated, Dedicated pool that you have created already.
- If you did not create the pool yet, create a new pool and put any available VM at the Destination in the pool. The VM that you put will just be a placeholder to create the pool. Once the pool is created, you can remove the placeholder VM and only keep your moved virtual desktops.
- Go to the Entitlements tab and add any user group or users to be entitled to get desktops from the pool. Most likely, it will the the same user group or user that was entitled to the pool on the Source side.
- Select the Inventory tab and click the Add button.
- Add the desktop VM that you just moved.
- Check the status of the desktop VM. First, the status will say “Waiting for agent,” then “In progress,” then “Available.”
- Right click on the desktop VM and select Assign User.
- Select the correct Active Directory user for the desktop.
- As the user to login to the virtual desktop using Horizon View Client or login on behalf of the user.
- For the first login after the move, the user may be asked by Windows to “Restart Now” or “Restart Later.” Please direct the user to “Restart Now.”
- After the restart, the user may utilize the Horizon View Client to login to the Destination’s moved desktop normally.
What’s next for Virtual Desktop Infrastructure?
Greetings CIOs, IT Managers, VM-ers, Cisco-ites, Microsoftians, and all other End-Users out there… Yury here. Yury Magalif. Inviting you now to take another virtual trip with me to the cloud, or at least to your data center. As Practice Manager at CDI, your company is depending on my team of seven (plus or minus a consultant or two) to manage the implementation of virtualized computing including hardware, software, equipment, service optimization, monitoring, provisioning, etc. And you thought we were sitting behind the helpdesk and concerned only with front-end connectivity. Haha (still laughing) that’s a good one!
VDI: OUR JOURNEY BEGINS HERE
Allow me to paint a simple picture and add a splash of math to illustrate why your CIO expects so much from me and my team. Your company posted double-digit revenue growth for three years running and somehow, now, in Q2 of year four, finds itself in a long fourth down and 20 situation. (What? You don’t understand American football analogies? Okay, in the international language of auto-racing, we are 20 laps behind and just lost a wheel.) One thousand employees need new laptops, docking stations, flat panel displays, and related hardware. Complicating the matter are annual software licensing fees for a group of 200 but with only five simultaneous concurrent users worldwide. At $1,500 per user times 1,000, plus the $100 fee, your CIO has to decide how it will explain to the board that it plans to spend another 1.5 million dollars on IT just after Q1 closed down 40 percent and Q2 is looking to be even worse.
To read the rest of this blog, where I try something different, please go to my work blog page:
http://www.cdillc.com/whats-next-virtual-desktop-infrastructure/
Exchange 2010-2016 Database Availability Group (DAG) cluster timeout settings for VMware
Symptom:
Exchange 2010-2016 Database Availability Group (DAG) active database moves between DAG nodes without any reason, when the DAG nodes are VMware Virtual Machines. This may be due to the DAG node being VMotioned by vSphere DRS cluster.
Solution:
The settings below allow you to VMotion without DAG active databases flipping between nodes for no reason.
Although the tip below is mainly useful for Multi-Site DAG clusters, I have seen this flipping happen even within the same site. So, the recommendation is to do these commands on ANY DAG cluster that is running on VMware.
Instructions:
Substitute your DAG name for an example DAG name below, yourDAGname or rpsdag01.
On any Mailbox Role DAG cluster node, open Windows PowerShell with modules loaded.
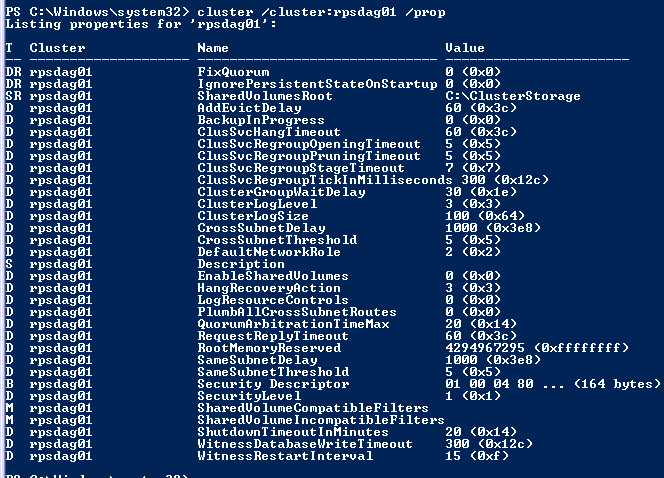
| Type the following command to check current settings:
cluster /cluster:yourDAGname /prop Note the following Values: SameSubnetDelay SameSubnetThreshold CrossSubnetDelay CrossSubnetThreshold |
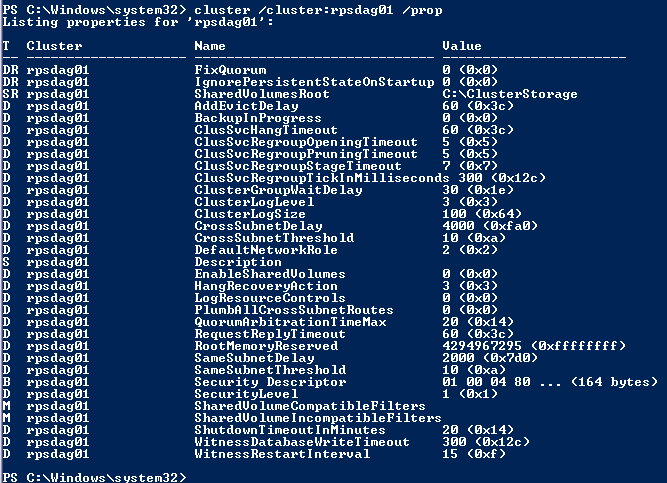
| Type the following commands to change the timeout settings.
cluster /cluster:yourDAGname /prop SameSubnetDelay=2000 cluster /cluster:yourDAGname /prop SameSubnetThreshold=10 cluster /cluster:yourDAGname /prop CrossSubnetDelay=4000 cluster /cluster:yourDAGname /prop CrossSubnetThreshold=10 |

Type the command to check that settings took
cluster /cluster:yourDAGname /prop
You ONLY need to run this on ONE DAG node. It will be replicated to ALL the other DAG nodes.
More Information:
See the article below:
http://technet.microsoft.com/en-us/library/dd197562(v=ws.10).aspx
Collateral for my presentation at the New Jersey VMware User Group (NJ VMUG)
I was delighted at the chance to present at the New Jersey VMware User Group (NJ VMUG). The attendees posed excellent questions.
Thank you much to Ben Liebowitz for the invitation.
My presentation is called “Virtual Desktop (VDI) Performance Troubleshooting”
Here are the slides for the session:
Virtual Desktops (VDI) on an Airplane
Recently, while flying on United Airlines I noticed the WiFi sign on the seat in front. I never used WiFi on planes before, so I thought it would be expensive. Imagine my surprise when it was cheap. It was probably cheap to compensate the absence of TV displays.
I immediately thought of our CDI Virtual Desktop (VDI) lab in Teterboro, NJ (USA). Would the Virtual Desktop even be usable? How will video run? I connected immediately, started recording my screen and opened my Virtual Desktop. It worked! Everything except video worked well.
My idea came because of Michael Webster, who has already tried doing this and wrote about it. I also wanted to do it in the Gunnar Berger style of protocol comparison. So, for your viewing pleasure — Virtual Desktops (VDI) on an Airplane.
——
Description:
This video is a demonstration of the Virtual Desktop (VDI) technology, located at CDI in Teterboro, NJ (USA) being accessed from an airplane 34,000 feet (10 km) high. Virtual Desktops allow you to use your Windows desktop from anywhere — even on satellite based WiFi. You will see PCoIP and HTML5 tests, Microsoft Word, HD video, YouTube video and vSphere client utilization.
Demonstration: Yury Magalif.
Lab Build: Chris Ruotolo.
Connecting From: Random clouds above Missouri, USA
Equipment and Software used:
VMware View
VMware vSphere
Cisco C-series servers.
EMC XtremIO all flash storage array.
10Zig Apex 2800 PCoIP acceleration card with a Teradici chip.
Inspired by:
Michael Webster’s blog article:
The VMware View from the Horizon at 38,000 Feet and 8000 Miles Away
Gunnar Berger’s low-latency VDI comparison video:
How to disable cluster shared volumes (CSV) on Windows Server 2008 R2.
Description:
Cluster Shared Volumes (CSV) are shared drives holding an NTFS volume that can be written to by all cluster nodes in a Windows Server Failover Cluster.
They are especially important for Microsoft Hyper-V virtualization, because all host servers can see the same volume and can store multiple Virtual Machines on that volume. Using CSVs will allow Windows to perform Live Migration with less timeouts.
Unfortunately, many third party applications do not support CSVs. In addition, CSVs can be much harder to troubleshoot.
Instructions:
If you need to disable CSVs, use the following command in PowerShell:
Get-Cluster | %{$_.EnableSharedVolumes = “Disabled”}
References:
http://windowsitpro.com/windows/q-how-can-i-disable-cluster-shared-volumes-windows-server-2008-r2
